5
大型语言模型的社会后果
大型语言模型已经彻底改变了我们与计算机互动的方式。它们能够理解自然语言并对复杂的问题作出反应。随着人工智能驱动的LLMs(如ChatGPT)的发展,它们已经变得越来越有用并走向通用。
然而,它们的迅速进展也不是没有争议的。许多人担心如此强大的技术所带来的反响,忧虑这些模型可能被用来操纵信息或替代人类的经验。为了充分了解它们的范围和力量,探索LLMs如何影响社会的不同方面非常重要。
鉴于这些开创性的模型的广泛采用所带来的巨大可能性和潜在风险,社会已经对其使用产生了不同的反应。例如,在开发和分发这些模型的源代码时,是采取开源还是闭源方式?
总的来说,开源是指任何人都可以免费使用、修改和发布的源代码,而闭源是指不能在创造它的机构之外修改或发布的专有代码。在GPT-3之前,大多数大型语言模型都是开源的,但目前,越来越多的公司将他们的模型变成闭源的,例如PaLM、LaMDA和GPT-4。在OpenAI宣布GPT-4模型的文件中,该公司说它不会提供关于架构、模型大小、硬件、训练计算、数据构建或用于开发GPT-4的训练方法的细节,只是指出它使用了从人类反馈中强化学习的方法,声称这是由于竞争和安全方面的考虑(AI Now Institute, 2023)。
同样,出于大型语言模型的竞争格局和安全问题,OpenAI向客户提供的付费访问,对如何使用有许多法律和技术限制。这使得学术研究人员更难进行LLM训练实验。对研究界来说,最直接的问题之一是缺乏透明度。ChatGPT及其前身的基础训练集和LLMs是不公开的,科技公司可能会隐瞒其对话式AI的内部运作。这与透明度和开放科学的趋势背道而驰。在这种情况下,有关人工智能的模型能力的主张无法被其他人验证或复制。客户也不可能下载ChatGPT背后的模型。
相比之下,开源工作涉及到创建一个模型,然后将其发布给任何人,让他们根据自己的需要使用、改进或改编。业界推动开源LLM的工作,承诺多方合作和权力共享,而这正是互联网的最初理想。它显示了不同的社区如何能够相互帮助,携手推进大型语言模型的下一步发展。
围绕着LLMs的另一个关键问题是它们的伦理含义。随着这些系统变得越来越复杂,有关操纵人类行为或公众舆论的问题日益凸显。此外,LLMs有可能被用作恶意行为者或组织获取私人数据或传播虚假信息的工具。出于对偏见和准确性的担忧,人们也担心它们在医疗诊断、法律决定甚至政府政策中的使用。
“深度伪造”(deepfake),由人工智能创造的图像和视频,已经在媒体、娱乐和政治中出现了。在此之前,创造深度伪造的内容需要相当多的计算技能。然而,现在,几乎任何人都能创造它们。OpenAI已经试图通过在每张DALL-E 2的图像上“打上水印”来控制虚假图像,但未来可能需要更多的控制手段——特别是当生成式视频创作成为主流时。
生成式人工智能还提出了许多有关何为原创和专有内容的问题。由于创建的文本和图像与以前的任何内容都不完全一样,AI系统供应商认为人工智能生成内容属于提示的创造者。但它们显然是用于训练模型的先前文本和图像的衍生品。不用说,类似技术将在未来几年为知识产权律师提供大量工作。
在隐私方面,LLMs本质上是个人化的,它收集大量的用户数据,以便能够有效地预测对话的长度、主题和轨迹。此外,每次与 ChatGPT 这样的工具的互动都有一个唯一的标识符——有使用它的人的登录轨迹。因此,个人对 ChatGPT 的使用并非真正的匿名,这就引发了有关 OpenAI 保留敏感数据的问题。围绕着数据的收集、存储和使用,必须进行一系列的考虑,以便安全地使用LLMs。
LLMs与其他人工智能技术一样受到监管和合规框架的约束,但随着它们变得越来越普遍,可能会提出新的问题:如何以符合《通用数据保护条例》(GDPR)和其他法规的方式使用此类工具。由于 ChatGPT 处理用户数据以生成响应,OpenAI 或者出于自身目的而依赖 ChatGPT 的实体可能被视为 GDPR 下的数据控制者,这意味着它们应该获得处理用户个人数据的合法依据(例如用户的同意),并且必须告知用户它们在从事何种由 ChatGPT 支持的数据处理活动。
所有这些潜在的问题强调了为什么科学家、研究人员和其他使用LLMs的人或组织在将其投入实际使用之前,从多个角度积极审查大型语言模型的影响是至关重要的。如果深思熟虑地考量伦理方面的影响,再加上严格的安全措施,大型语言模型就可以成为有价值的工具,而不会破坏用户的信任或损害完整性。
此外,虽然大型语言模型的趋势仍在继续,但重要的是要注意,更大并不总是意味着更好。大型语言模型可以很好地进行随心所欲的创造性互动,但过去十年的发展告诉我们,大型深度学习模型是高度不可预测的,使模型更大、更复杂并不能解决这个问题。
像ChatGPT这样的大型语言模型,具有与用户进行类似语言交流的能力,有可能成为交流和教育以及其他许多领域的强大工具。然而,一方面其对社会的影响是巨大的;另一方面其被滥用的可能性也是非常真实的。因此,需要更多的研究来认识大型语言模型的社会后果及对我们生活的影响。随着人工智能和数据科学越来越多地融入到日常生活中,重要的是要加强这类技术的伦理考量,并尊重我们的数据和隐私赋予我们的个人权利。该领域的领导者必须共同努力,确保大型语言模型的使用是负责任的,符合人类的最佳利益。
6
大型语言模型带来的交流困境
ChatGPT和其他生成式人工智能工具正在将有关大型语言模型的对话带到公众关注的最前沿,并且带着一种前所未有的紧迫感。现在,人们必须就人工智能的未来是什么样子以及如何创造我们想要的未来进行交流。

我们需要传播理论、传播研究和基于伦理的传播实践来关注和指导这样的对话。数字人文学者马修·科申鲍姆(Matthew Kirschenbaum)预测,即将到来的“文本末日”将导致“文本海啸”,“在任何数字环境中都无法可靠地进行交流”(Kirschenbaum, 2023)。
科申鲍姆所称的“文本末日”是指,我们与书面文字的关系正在发生根本性的变化。通过ChatGPT等程序,所谓的生成式人工智能已经成为主流,这些程序使用大型语言模型来统计预测序列中的下一个字母或单词,从而生成模仿其所训练的文本内容的句子和段落。它们为整个互联网带来了类似自动完成(autocomplete)的功能。
目前,人们仍然在为这些程序输入实际的提示信息,同样,这些模型(大部分)仍然是根据人类散文而不是机器自制的作品进行训练的。但情况可能会发生变化——OpenAI发布ChatGPT应用程序接口就证明了这一点,它将允许该技术直接集成到社交媒体和在线购物等网络应用中(Wiggers, 2023)。不难想象,在这种情况下,机器可以促使其他机器无休止地发布文本,从而使互联网充斥着没有人类的能动性或意图的合成文本。
2022年6月3日,人工智能研究者兼YouTuber扬尼克·基尔彻(Yannic Kilcher)发布了一段视频,介绍他如何开发名为“GPT-4chan”的人工智能模型,然后部署机器人在著名留言板4chan上伪装成人类。4chan常被描述为互联网亚文化的中心,其社区对知名互联网模因的形成和普及以及黑客行动和政治运动具有相当大的影响力。4chan经常作为争议来源而受到媒体关注,包括协调组织针对某些网站和用户的恶作剧和骚扰,以及发布非法和攻击性内容。
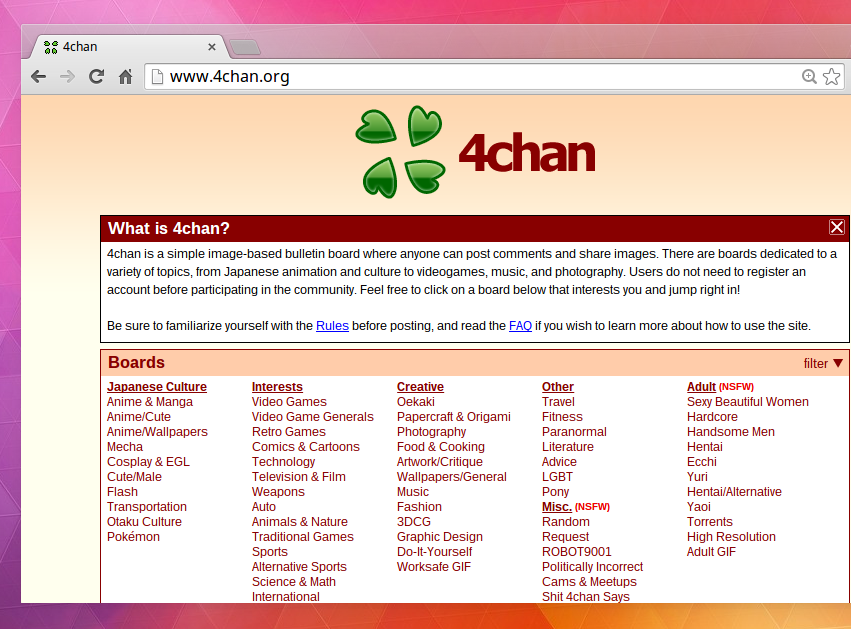
GPT-4chan是一个大型语言模型,通过使用之前公开发布的数据集对GPT-J进行微调来模拟4chan的/pol/匿名留言板用户而创建;其中许多用户经常表达种族主义、白人至上主义、反犹主义、反穆斯林、厌恶女性和反 LGBT的观点。基尔彻训练机器人阅读了4Chan这一臭名昭著的“政治不正确”板块3年半时间内的1.345亿条帖子,很自然地,该模型学会了输出各种仇恨言论,导致基尔彻称其为“互联网上最可怕的模型”,并在他的视频中这样说道:“这个模型很好,但从一个可怕的意义上来说……它完美概括了/pol/上大多数帖子中渗透的攻击性、虚无主义、恶搞以及对任何信息的深度不信任。”(Kilcher, 2022)
在训练完成后,由该模型驱动的10个机器人被部署在/pol/留言板上,24小时内匿名发布了15,000条基本上是有毒的信息。虽说许多用户通过留言板上的发帖频率很快认定这是一个机器人,而基尔彻也公布了在服务器上运行模型所需的代码和已训练的模型实例,并表示人工智能研究人员可以联系他获取机器人与4chan用户的互动记录,他的做法还是在人工智能研究者社区内引发了较大争议。
GPT-4chan模型发布在Hugging Face上,这是一个共享经过训练的AI模型的中心。在该模型被下载了1000余次后,Hugging Space团队首先“限制”了对它的访问,此后不久,他们又完全删除了对它的访问权限,其页面现在刊有以下免责声明:“已禁用对该模型的访问——鉴于其研究范围,在所有禁止使用机器人的网站上故意使用该模型生成有害内容(不完全示例包括:仇恨言论、垃圾邮件生成、假新闻、骚扰和辱骂、贬低和诽谤)被视为对该模型的滥用。”(Kurenkov, 2022)
在人工智能研究界,有人认为这样的模型很可能造成伤害,特别是在面向青少年的论坛中;让机器人与 4chan 用户互动是不道德的;它加剧了4chan本已有毒的回声室效应并进一步分化了用户群。阿德莱德大学的人工智能安全研究员劳伦·奥克登-雷纳(Lauren Oakden-Rayner)在一条推文中指责基尔彻“在未告知用户、未经同意或监督的情况下进行人类实验”。她认为这违反了人类研究伦理的所有原则(Mellor, 2022)。
基尔彻在接受The Verge采访时将该项目描述为一个“恶作剧”,他认为考虑到 4chan本身的性质,这种恶作剧几乎没有造成什么有害影响。“/pol/上完全可以预料到会有机器人和非常粗鲁的言谈。”(Vincent, 2022)并且,任何潜在的危害也可以使用其他现有模型来实现。
的确,基尔彻不会是第一个、也不是唯一一个创建恶意的微调模型的人。所以,问题在于,如果出现更多的微调模型,其内容指向在意识形态层面复制一种特定世界观,会为未来的人类交流带来什么?
基尔彻创建的机器人非常逼真。“它能对上下文作出反应,并能连贯地讲述在收集最后一次训练数据很久之后发生的事情和事件”,基尔彻在视频中称。以此类推,有人可以建立一个系统,让ChatGPT这样的程序反复向自己提问,并自动将输出结果发布到网站或社交媒体上。这样无休止地迭代内容流,除了在交流场域造成混乱,它还将被再次吸入大型语言模型的训练集,让模型在互联网上制造自己的新内容。如果各路人马——无论是出于广告收入、政治或意识形态目的还是恶作剧——都开始这样做,每天难以数计的类似帖子充斥在开放的互联网上,与搜索结果混杂在一起,在社交媒体平台上传播,渗透到维基百科词条中,尤其是为未来的机器学习系统提供素材,那将会怎样?

▲ Tay the Racist Chatbot
将基尔彻的工作与过去最著名的变坏了的机器人的例子相比较是非常有趣的:微软的Tay。微软于2016年在 Twitter上发布了人工智能聊天机器人,但在用户教导Tay重复各种种族主义和煽动性言论后,不到24小时,微软就被迫下线该项目(Vincent, 2016)。可是在那时,创建这样的机器人专属于大型科技公司的领域,基尔彻现在的做法表明,任何一人编码团队都可以使用更先进的人工智能工具达成同样的结果。至于说到人类研究伦理的指责,如果基尔彻在大学工作,让AI机器人在 4chan上自由活动可能是不道德的。但基尔彻坚称自己只是一名YouTuber,这暗示着他认为此处适用不同的伦理规则。
面对如此严峻的局面,我们该如何应对?笔者认为,传播学可以发挥作用的领域包括:
让开发者对人工智能偏见负责
像希瑟·伍兹(Heather S. Woods)和泰勒·莫兰(Taylor C. Moran)这样的传播研究者已经发表了关于人工智能虚拟助手(如Siri和Alexa)与性别和种族刻板印象的重要研究成果,显示了人工智能是如何反映并重新定义人类偏见和价值观的(Woods, 2018; Moran, 2021)。随着生成式人工智能和新应用的引入,这一领域还需要更多的研究。研究的目的是唤醒公众去追究那些生产强化此类偏见的人工智能软件组织的责任。
具体就大型语言模型而言,一件重要的事情是帮助制订发布“基础性”模型的社区规范。斯坦福以人为本人工智能研究院(HAI,Human-Centered AI Institute)和基础模型研究中心(CRFM, Center for Research on Foundation Models)就提出,随着基础模型变得更加强大和普遍,负责任发布的问题变得至关重要(Liang, 2022)。而“发布”一词本身就有不同的内涵:首先是研究访问,即基础模型开发者令外部研究人员可以访问数据、代码和模型等资产;而部署到用户中开展测试和收集反馈,以及以产品形式部署到最终用户中,则构成了更深入的发布形式。
随着AI技术变得越来越强大,每个基础模型开发者独立决定其发布政策的问题凸显出来。原因有二:首先,单个行为者发布不安全、功能强大的技术可能会对个人和社会造成重大伤害。即便认为当今基础模型的风险还没有严重到有理由限制相对开放的发布,然而快速的发展速度也给未来模型的能力带来了相当大的不确定性。其次,正因为基础模型风险的严重性尚不明确,基础模型开发者将从分享最佳实践中获益,而无需每个组织都重新发明轮子,承担重新发现某些危害的经济和社会成本。此外,加强合作和提高透明度可以解决集体行动问题,即由于快速行动的强烈经济动机,各组织通常对负责任的人工智能投资不足(Askell et al, 2019; 胡泳,朱政德,2023)。底线就是,需要社区规范来管理基础模型的发布。在向公众发布人工智能代码或模型时,既要考虑这样做的直接影响,也要考虑其他人使用这些代码或模型可能产生的下游影响。
完善把关机制,限制访问或移除可能有害的模型和数据集
随着AI逐渐成为各类信息和知识的把关人,为AI系统设置把关人成为迫切需要。例如,基尔彻使用的数据集过去和现在都是公开的,任何人都可以下载,因此可以想象,拥有人工智能技术的人有可能会用它来创建一个以传播仇恨言论为目的的机器人。一旦这样的机器人公开发布,像本文中提到的Hugging Face拔掉下载插头的把关行为就是值得称许的。
2020年7月,麻省理工学院下线了一个庞大且被高度引用的数据集,因为两名研究人员发现该数据集使用种族主义和厌恶女性的术语来描述黑人/亚洲人和女性的图像。这一名为“8000万张小图像”(80 Million Tiny Images)的训练集是在2008年创建的,目的是开发先进的物体检测技术。它被用来教授机器学习模型识别静态图像中的人和物体(Quach, 2020)。
在技术新闻网站The Register向大学发出警报后,麻省理工学院删除了数据集,并敦促研究人员和开发人员停止使用该训练库,并删除所有副本。大学还在其网站上发表了官方声明并道歉(Ustik, 2020)。
这种道德上可疑的数据集所造成的损害远远超出了不良品味;该数据集被输入神经网络,教导它们将图像与单词关联起来。这意味着任何使用此类数据集的人工智能模型都在学习种族主义和性别歧视,而这可能会导致带有性别歧视或种族主义的聊天机器人、存在种族偏见的软件,甚至更糟的社会后果,比如警方使用人脸识别系统误认某人、并因其未曾犯下的罪行而实施逮捕的案件(Hill, 2020)。
部分问题在于数据集是如何构建的。“8000万张小图像”包含2006年根据 WordNet(一个用于计算语言学和自然语言处理的英语单词数据库)的查询从互联网上抓取的 79,302,017 张图像。据创建者介绍,他们直接从WordNet复制了 53,000多个名词,然后自动从各个搜索引擎下载与这些名词相对应的图像。由于WordNet包含贬义术语,用户最终会得到无意中证实和强化刻板印象及有害偏见的结果(Song, 2020; Kurenkov, 2022)。
另一个有问题的数据集是ImageNet。ImageNet是一个大型视觉数据库,用于视觉对象识别软件研究。2019年,在一个名为ImageNet Roulette的艺术项目显示数据集当中存在系统性偏见后,ImageNet也从其系统中删除了60万张照片。不出所料,ImageNet也是基于WordNet构建的(Ruiz, 2019)。这表明了对数据集实施把关的必要性,如果不加以控制,它将继续产生有偏见的算法,并为使用它作为训练集的人工智能模型带来偏见。就像计算机科学领域的一句著名习语所说的:垃圾进,垃圾出。

把关机制既包括Hugging Face这样的神经语言编程代码共享平台,也包括麻省理工学院这样的精英大学,还需要The Register这样的技术媒体进行社会监督。人工智能研究社区也要着力培养包容性文化,建立更符合伦理的数据集,并规范自身的程序:例如,避免使用知识共享(Creative Commons)材料,获得明确的数据采集同意,并在数据集中加入审计卡(audit card),允许数据集的管理者公布目标、管理程序、已知缺陷和注意事项。
一个例证是,模型发布时应包含有关模型文档的模型卡(model card),它是记录已发布的人工智能模型的预期用途和局限性的好方法,比如GPT-4chan的模型卡就明确指出了它的仇恨言论倾向,并警告不要部署它。
重新思考内容的生产与传播
威廉·萨菲尔(William Safire)是20 世纪90年代末最早断言“内容”(content)将作为独特的互联网类别而兴起的人之一(Safire, 1998),或许也是第一个指出内容无需与真实性或准确性相关即可实现其基本功能的人。这一基本功能,简单来说,就是存在;或者,如凯特·艾希霍恩(Kate Eichhorn)所指出的,内容可以不传递任何信息或知识,只是为了流通而流通(Eichhorn, 2022)。
从ICP时代以来,内容就被放置于社会文化和经济发展中至关重要的位置,在经历了PGC、UGC、PUGC这些不同内容模式和内容经济之后,内容已经成为人们日常生活审美化、艺术化、商品化的重要组成部分。然而在如今风起云涌的AIGC浪潮中,主体和历史双双迎来了史无前例的危机,因为这场生成式革命选择将人类更深层次的编码能力和思维链能力通过训练交付给机器(胡泳,刘纯懿,2023)。当代文化产业的规范正在朝着书面语言的自动化和算法优化方向发展。大量生产低质量文章以吸引广告的内容农场使用了这些工具,但它们仍然依赖大量的人力将字符串成适当的单词,将单词串成清晰的句子,将句子串成连贯的段落。一旦自动化和扩大劳动规模成为可能,会出现什么动力来控制这种生产呢?
长期以来,内容的基本范式一直是所谓“读写网”(read-write web)。我们不仅消费内容,还可以生产内容,通过编辑、评论和上传参与网络的创建。然而我们现在正处于一种“自书写网络”(write-write web)的边缘:网络不断地书写和重写自身。毕竟,ChatGPT及其同类工具可以像写文章一样轻松地编写代码。
从本质上来说,我们将面临一场永无止尽的信息垃圾危机,由一种人类和机器作者的脆弱融合体加以催生。从芬·布朗顿(Finn Brunton)的《信息垃圾:互联网的影子历史》(Spam: A Shadow History of the Internet,2013)一书中,我们可以了解在互联网上传播虚假内容的五花八门的方法,例如“双面”网站,即为人类读者设计的网页和为搜索引擎中的机器人爬虫优化的网页同时并存;搭建整个由自主内容填充的博客网,以驱动链接和流量;“算法新闻”,通过网络发布自动报道;当然还有在2016年美国大选和英国脱欧期间声名鹊起的僵尸网(botnet)(Brunton, 2013)。形形色色、具有威胁性的信息垃圾告诉我们,网络的自我书写已经持续一段时间了。今天,随着生成式人工智能开始占据主导地位,可以预计,机器生产的文本将堵塞服务器、通信电缆和数据中心。

内容生产与传播的新乱象为传播学带来了大量富于挑战的课题:比如用户生成内容与有报酬(尽管常常报酬不足)的工人制作的内容的区别;全球底层社会中的隐形工人,他们让人工智能看起来很“聪明”,然而自身却是受技术负面影响最大的边缘化群体;从艺术和文学到新闻和政治,这些领域如何经受AIGC内容产业崛起的考验;是否存在某种“内容资本”,即艺术家、作家和表演者制作内容的能力,并不关乎他们的作品,而是和他们作为创造者的地位息息相关?
解决人工智能和传播的职业问题
乔舒亚·里夫斯(Joshua Reeves)写道:“面对机器冷冰冰的效率,人类似乎只是潜在错误的有机集合。”(Reeves, 2016)OpenAI的研究预测,“80%的美国劳动力可能至少有10%的工作任务会受到LLM的影响”。更糟糕的是,“19%的工作者可能会看到至少50%的工作任务受到影响”(Eloundou et al, 2023)。公共关系专业人士、文案撰稿人、平面设计师、社交媒体营销人员——这些都是本科主修传播学的人的常见职业,也都可能受到快速生成文本和图像的生成式人工智能的威胁。传播学需要研究如何在各种传播工作环境中合乎伦理地使用人工智能工具,也需要通过专业主义的倡导来保护这些职业。
在研究、交流中和课堂上提升人工智能素养
奥特姆·爱德华兹(Autumn Edwards)和查德·爱德华兹(Chad Edwards)等传播教育研究者试图展示人工智能如何改变传播教学的本质(Edwards, Edwards, 2017)。此外,ChatGPT带来的有关考核方式和学术不诚实的大量讨论为传播学学者提供了一个机会,调查和挑战我们对教学和学习的假设。我们还应该借鉴传播学研究中将新媒体技术融入课堂的悠久历史,确定在哪些实践中使用人工智能将有利于促进学生学习和提高教学质量。此外,就像社交媒体和假新闻的兴起要求发展更好的媒介素养一样,ChatGPT等工具要求人工智能素养的培育,传播学在这方面责无旁贷。需要大力开展科学传播,动员人工智能社区中更多的研究人员扮演AI传播者的角色,让更多的公众了解AI技术的能力和局限性。
对传播学进行重新定位和重新概念化
最终,回到传播学研究本身,是否需要对传播学进行重新定位和重新概念化,以适应日益智能的机器、自主决策系统和智能设备带来的机遇和挑战?从历史上看,传播学通过将创新性突破转化为人类互动和信息交换的媒介来适应新技术。随着计算机的发展,20 世纪下半叶出现了以计算机为媒介的交流(CMC)。在CMC研究中,计算机被理解为或多或少中立的讯息传输渠道和人类交互工具。这种形式化忽略了这样一个事实:与以前的技术进步不同,计算机在今天开始占据交流交换参与者的地位。人工智能科学中已经存在不少这方面的证据,所以,我们也许要问:CMC 范式虽然具有不可否认的影响力,但是否存在重大不足,甚至不再站得住脚?相应地,传播学是否需要重新设计基本框架,以应对独特的技术挑战及社会机遇?现在是传播学认真对待这些关键问题的时候了。
尽管人工智能有效地挑战了当前的范式,将其正常功能置于某种危机之中,但构成新范式的内容,现在才刚刚开始出现。按照科学史的发展逻辑,这些创新可能需要相当长的一段时间,才能被定型并编入下一次被视为“正常科学”的迭代中。然而,在当前这个初步阶段,我们可以开始确定,随着人工智能技术的进展,下一代传播研究可能会是什么样子。
(原载《新闻记者》2023年第8期,注释从略)

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}