内容摘要:ChatGPT爆火后,老牌巨头、后起新锐纷纷涌入大语言模型赛道,掀起一波生成式人工智能代理热潮。实际上,人工智能代理并不是一个新兴概念,其历史可追溯至互联网诞生之初,其蕴含于过往的媒介想象中,经历了从理念建构到实践落地的范式转型。可借鉴媒介考古学的媒介史研究视角,通过重访与串联那些未被重视的历史细节,勾勒关于人工智能代理的媒介想象与传播史线索。新近涌现的生成式人工智能代理的技术路线与平台模式呈现若干特征。围绕人工智能代理展开的媒介实践史生动地呈现了新旧媒介的交错、纠缠与融合。如今,被视为“下一个平台”的生成式人工智能代理本质上是大语言模型范式的实体化产物,其开发与应用深嵌于以算力资源为核心的基础设施网络,而后者早已呈现日益深化的平台化趋势。
//目录
一、引言
二、未来考古:从未来想象到翻译传播
(一)人类助手与电子管家
(二)软件代理人
(三)中文译法之辨
三、历史脉络:从理念建构到实践成形
(一)初探期(1956—1995年):概念实体化
(二)分化期(1996—2011年):产品类型化
(三)涌现期(2012年以来):功能通用化
四、前沿趋势:生成式人工智能代理
(一)拟真式环境:游戏版真实世界
(二)交互式学习:社会化智能主体
(三)生成式智能:通用人工智能之路
五、余论:平台化渗透人工智能市场
一、引言
2023年4月7日,斯坦福大学与谷歌(Google)公司的研究者们发表了一篇轰动人工智能领域的论文。他们构建了一个名为“Smallville”的虚拟小镇,25个人工智能代理在这个交互式沙盒环境中模拟人类行为——它们在小镇散步、约会、聊天、用餐以及分享当天的新闻,可谓让美剧《西部世界》走进现实。此后,Voyager、GITM、SIMA等生成式人工智能代理涌现出来,被视为强大的通用问题求解器。2023年11月,微软(Microsoft)公司创始人比尔·盖茨(Bill Gates)在文章《人工智能即将彻底改变你使用计算机的方式》(AI Is about to Completely Change How You Use Computers)中描绘了人工智能代理成为“平台”(platform)的未来景观:“在计算行业,我们谈论平台——构建应用程序和服务的技术。Android、iOS和Windows都是平台。人工智能代理将是下一个平台。”
此前,源自西方的“平台”概念被定义为一种旨在组织用户之间交互的可编程架构,主要指由美国的五大科技巨头GAFAM(Google-Alphabet,Amazon,Facebook-Meta,Apple和Microsoft)主导的社交媒体和其他数字服务市场;“平台化”(platformization)则被用来描述平台作为社交网络的主导基础设施和经济模式的崛起,以及社交媒体平台扩展到其他在线空间的后果。如今,孕育于人工智能领域的新型平台备受瞩目:新锐科技公司OpenAI于2022年11月30日发布GPT-3.5大语言模型以及根据该模型进行微调的聊天机器人程序ChatGPT,又于2024年年初推出GPT商店(GPT Store),引发社会对新一波人工智能热潮的追捧,大语言模型被视为正在崛起的新型平台,而基于大语言模型的人工智能代理亦展现出平台的潜力。
传统的线性媒介史叙事或新媒体研究往往并不在意作为“旁枝末节”的媒介技术实践,重在考察某种特定的媒介技术之于社会变迁的功能性作用;在这一媒介研究视野下,2023年以来人们津津乐道的“AI Agent”(人工智能代理)被描述为具有革新与颠覆意义的全新媒介技术。然而,被忽略的丰富历史碎片表明,“AI Agent”并不是一个新兴概念,关于技术代理的媒介想象与技术实践早已有之,对“agent”的使用甚至可以追溯到20世纪互联网诞生之初。从媒介考古的历史研究视角来看,“当下”与“未来”或许早已潜藏于“过去”之中,即便是偶一为之的“幻想媒介”(imaginary media)也可能不同程度上左右了媒介的发明与实践。因此,对媒介运作机制或权力关系的讨论不能脱离设备、系统、编程、平台等物质基础,研究者应重访更为丰富与复杂的媒介实践历史,考察那些似曾相识的媒介变体如何交错纠缠、循环往复。
借鉴媒介考古学的媒介史观考掘人工智能代理的技术实践史,或将揭开当下科技市场热点“智能体”的神秘面纱。人工智能的技术实践何以演进至今,又将通往何处?人工智能代理经历了怎样的“前世今生”?新一波生成式智能代理的技术路线有哪些特征?人工智能代理领域缘何呈现鲜明的平台化趋势?以这些问题为指引,本文将重访未被重视的关于人工智能代理的未来想象与传播历史,梳理其从理念建构到实践成形的历史脉络,再落脚到当下技术实践的物质基础,以此窥见科技行业的平台化趋势。
二、未来考古:从未来想象到翻译传播
“未来考古学”(prospective archaeology)是德国学者西格弗里德·齐林斯基(Siegfried Zielinski)近年来重点关注的媒介研究路径,意在重构古老的媒介机器以期获知过去以及可能的未来,从而提供一种不同于线性目的论的历史叙述方式。与齐林斯基的技术路径相比,“未来考古学”在偏向文本路径的文学研究领域的根基更为深厚。美国文学研究学者弗雷德里克·詹姆逊(Fredric Jameson)在《未来考古学:乌托邦欲望和其他科幻小说》(2005)一书中提出的“未来考古学”(archaeologies of the future),从历史角度审视文学文本中的乌托邦世界与现世社会意识形态之关联。两条路径的媒介考古意识并不相同,却为审视既新亦旧的“人工智能代理”媒介提供了镜鉴——作为媒介的技术代理周而复始地浮沉于历史之中,对其进行“未来考古”,就是对历史过程中关于技术代理的未来想象及传播进行发掘、考据与剖析。
(一)人类助手与电子管家
技术代理的未来想象文本,在1995年两部摹画即将到来的数字化时代的力作中可以清晰地看到。盖茨在《未来之路》(The Road Ahead)一书中主张将扮演人类助手角色的“agent”视为内置于软件中的合作者,其通过不断学习计算机捕捉到的用户与界面的交互行为,以类似人际交谈的形式为用户提供帮助。.同年,盖茨的这一设想在微软的人机界面Bob中得到尝试,其内置虚拟助手,指引用户在主界面或应用程序中执行任务。在Bob失败之后,微软又在1997年推出Office助手Clippy,其形似回形针,位于电脑屏幕的一边,意在帮助用户掌握不易使用的软件。然而Clippy由于交互体验令人沮丧也未能成功。
计算机科学家尼古拉·尼葛洛庞帝(Nicholas Negroponte)比盖茨更早意识到人机交互的未来将建立在“agent”的基础上。1970年,他最早将“agent”描述为电子“管家”,其可以执行过滤电子邮件、安排约会、通知投资和安排旅行等任务。在1995年的畅销书《数字化生存》(Being Digital)中,他写道:“界面应该设计得像人一样,而不是像仪表板一样。”“未来,今天我们所谓的‘代理人界面’(agent-based interface)将崛起成为电脑和人类互相交谈的主要方式。”早在1967年,尼葛洛庞帝就在麻省理工学院(MIT)创建了媒体实验室(Media Lab)的前身建筑机器小组(Architecture Machine Group,ArcMac),创建这一团队的部分灵感来自伊凡·苏泽兰(Ivan Sutherland)有关“画板”(Sketchpad)的博士论文,其对于计算机图形和界面设计都有着开创性的意义。实际上,苹果公司和微软公司的很多计算产品的想法出自尼葛洛庞帝早期对电脑在建筑领域影响的探究。尼葛洛庞帝的研究团队创造了一个名为“空间数据管理系统”的可视化数据管理系统原型,把系统设计得能让用户在30秒之内学会操作,其作为一种对“不同的尺寸、形状、颜色和语调”的界面的尝试,日后影响了苹果公司1987年的“知识导航员”(Knowledge Navigator)愿景和2011年面世的以会话为基础的人机交互系统Siri。
(二)软件代理人
在苹果公司的愿景中,用户与平板电脑的交互是通过软件代理人来实现的。这代表了一种与从前截然不同的人机交互模式。与被动的应用程序相比,一个代理人扮演的是更积极主动的角色,就像人类助手一样。代理人会以助手的身份与用户合作,积极配合用户做他想做的事情。到了20世纪90年代中期,在万维网迅速扩张的刺激下,人们对软件代理人的兴趣迅速增长。在媒体实验室追随尼葛洛庞帝的帕蒂·梅斯(Pattie Maes)早已开始开发代表用户完成任务的软件助理。1994年,她发表了一篇广受读者欢迎的文章,题为《代理人能够帮助人们减少工作量和信息过载》,文章描述了实验室开发的许多原型代理人的功用——电子邮件管理、会议日程安排、新闻过滤和音乐推荐等。1995年,梅斯和实验室的几个伙伴一起创立了Agents公司——一家音乐推荐服务公司。最终,这家公司被卖给微软公司,后者使用了该公司的隐私技术Firefly,但并没有对它最初的软件助理构想进行商业化。
随后的10年里,上百种类似的代理人问世,其中许多都基于互联网。软件代理技术似乎是一种很有前景的技术,而一大批软件开发公司,也很快成了网络泡沫的一部分。从互联网的大发展来讲,软件代理人只是其故事的很小一部分,但它却是跟人工智能相关的最明显的部分。如尼葛洛庞帝所说:“当我谈到界面代理人(interface agent)时,经常有人问我:‘你指的是人工智能吗?’答案是‘没错’。但是这个问题中夹杂着些微的怀疑,主要是因为过去人工智能给人们许多虚无的希望和过高的承诺。此外,很多人对机器能够拥有智慧这样的观念,仍然深感不安。”其实人工智能研究者的梦想并没有错,只是在那一时期太超前而已。
Siri是20世纪90年代软件代理人努力的直接产物,它是一个基于软件的代理人,用户可以用自然语言与之交互,它代替用户执行简单的任务。其他大众市场的应用商迅速跟进:亚马逊公司的Alexa、微软公司的Cortana和谷歌公司的Google Assistant都实现了类似功能。无一例外,它们都将开发起源追溯到基于代理人的人工智能,当然,实际上它们不可能在20世纪90年代出现,因为当时的硬件不足以支持其运行。曾担任Microsoft Bob营销经理的梅琳达·盖茨(Melinda Gates)2017年承认,该软件“需要一台比当时大多数人所拥有的电脑更加强大的电脑”。至少到2010年后,移动设备的计算能力才足以支持类似软件。
(三)中文译法之辨
“agent”是一个舶来的概念,其在进入中文语境的过程中衍生出不同的译法,主要包括“代理/代理人”与“智能体”两类。在中国刚刚接入国际互联网的20世纪90年代中期,前述两本预测未来科技的著作迅速被翻译成中文,由北京大学出版社出版于1996年的《未来之路》(辜正坤主译)将“agent”译为“代理者(程序)”,由海南出版社同年出版的《数字化生存》(胡泳、范海燕译)则将“agent”译为“代理人”。将人工智能领域的“agent”概念译为“代理(者/人)”的方式实际上都考虑到内含于技术物“agent”中的“委托代理”的经济逻辑。经典教科书《人工智能:一种现代方法》(Artificial Intelligence: A Modern Approach)的第一章和第二章指出,人工智能向经济学借用了术语“理性代理人”(rational agent)来表述具有目标导向的“智能代理”(intelligence agent),并指出,任何通过传感器(sensor)感知环境(environment)并通过执行器(actuator)作用于该环境的事物都可以被视为代理(agent)。
然而,人工智能学界从20世纪90年代初开始将“intelligent agent”翻译为“智能体”,在出版于2004年的中译本《人工智能:一种现代方法》中,“agent”与“intelligent agent”都被翻译为“智能体”。近年来,曾经被尼葛洛庞帝视为通往“界面代理人”未来图景的人工智能技术成功将当时的许多科幻想象转变为现实。同时,国内人工智能学界的学术发表仍以英文为主,并不重视中文语境下的概念内涵与外延。于是,在势不可当的人工智能热潮推动下,“AI Agent”被部分国内媒体与学界人士直接译作“AI智能体”或“智能体”,并被广泛传播。
虽然“智能体”相较于“人工智能代理”更为简短易记,但是这种译法不仅存在成分赘余之嫌,还遗失了其原初的“人帮助人”的经济学理念,忽略了将技术作为相对自主的“主体”的社会性命题。因此,在国内尚未形成统一使用规范的情况下,本文主张以“人工智能代理”或“人工智能主体”来指代正处于风口浪尖的英文“AI Agent”一词,其指的是一种能够理解、分析和响应人类输入的信息,并像人类一样执行任务、作出决策并与环境互动,通过行动来达成目标的自主实体。
三、历史脉络:从理念建构到实践成形
前文追溯了历史上关于“agent”的未来想象与翻译传播历程,那么诞生于英文语境的“AI Agent”理念与实践又经历了怎样的转型过程?人工智能领域的科学家、工程师们从探讨人工产品是否具有能动性(agency)的哲学概念及经济学中的代理人术语获得启发,拼凑出“AI Agent”这一概念,并推动其理念的落地与进化。
(一)初探期(1956—1995年):概念实体化
20世纪50年代,艾伦·图灵(Alan Turing)提出著名的图灵测试,以判断人工实体是否具有智能——如果人不能区分置于黑箱子里的机器是人还是机器的话,这台机器就被判定为有智能。这些人工智能实体通常被称为“agent”,成为人工智能系统的基本构建模块。由于人类只能观察到机器的外在行为,难以洞察形而上学的机器“意识”,包括图灵在内的许多人工智能研究人员都建议暂时搁置“agent”是否能够思考或拥有意识的辩题,而以自主性、反应性、主动性和社交性等属性来描述人工智能代理,将其从形而上的理论概念转化为“可见”的计算实体。
在人工智能发展的最初30年里,符号人工智能(symbolic AI)占据了主导地位,其受到数学逻辑以及人们描述自身思考过程的方式的启发,意在发展通用问题求解器,如专家系统。亚符号人工智能(subsymbolic AI)则从神经科学中汲取灵感,试图捕捉隐藏在“快速感知”(fast perception)背后的无意识思考过程,如识别人脸或语音等,一个早期的例子是感知机,由心理学家弗兰克·罗森布拉特(Frank Rosenblatt)于20世纪50年代末提出。20世纪50年代至60年代的人工智能,在符号演算和感知机两个方向上都陷入了停滞。于是,20世纪60年代末和70年代初,人工智能进入第一个寒冬。此后,以5至10年为周期,人工智能不断上演“春天”—过度承诺和媒体炒作—“寒冬”的循环。到20世纪80年代,虽然有若干聚焦面狭窄的专家系统得到了成功部署,但之前研究者承诺的更通用的人工智能突破并未实现。1987年,专家系统计算机市场崩溃,第二个人工智能寒冬到来,一直持续到2000年。
在漫长的人工智能寒冬中,人工智能学者仍然对“AI Agent”葆有浓厚兴趣。1995年,英国人工智能学者迈克尔·伍尔德里奇(Michael Wooldridge)和尼克·詹宁斯(Nicholas R. Jennings)将“AI Agent”定义为能够在某个环境中自主行动以实现其设计目标的计算实体。1998年,两人合编了《代理技术:基础、应用和市场》(Agent Technology: Foundations, Applications, and Markets),这是第一本综合介绍设计、构建和使用代理应用程序时遇到的问题、挑战的著作,既有对代理技术基础的概述,也有在实践中处理特定代理系统的报告。同期,美国人工智能学者彼得·诺维格(Peter Norvig)和斯图尔特·J.罗素(Stuart J. Russell)将“AI Agent”的类型细分为简单反射代理(simple reflex agents)、基于模型的代理(model-based agents)、基于目标的代理(goal-based agents)、基于实用程序的代理(utility-based agents)和学习型代理(learning agents)5类。至此,“AI Agent”概念获得了明确的功能指向和实践目标,利用人工智能技术开发的能够解决特定问题的软件或硬件都可被纳入人工智能代理范畴。
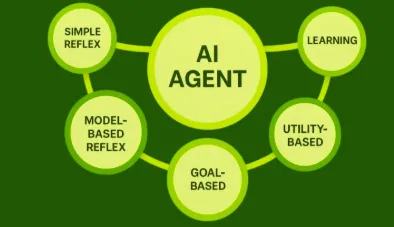
AI Agent的分类
(二)分化期(1996—2011年):产品类型化
根据人工智能研究者在20世纪90年代给出的定义,后来的围棋机器人AlphaGo、苹果手机助手Siri、天猫精灵智能音箱等技术产品都可以被纳入人工智能代理的范畴。此时,人工智能开发的目标从构建可以像人类一样选择的代理人转向构建能够作出最优选择的代理人。也就是说,是否通过图灵测试并不重要,重要的是,能否代替人类执行最优的选择。
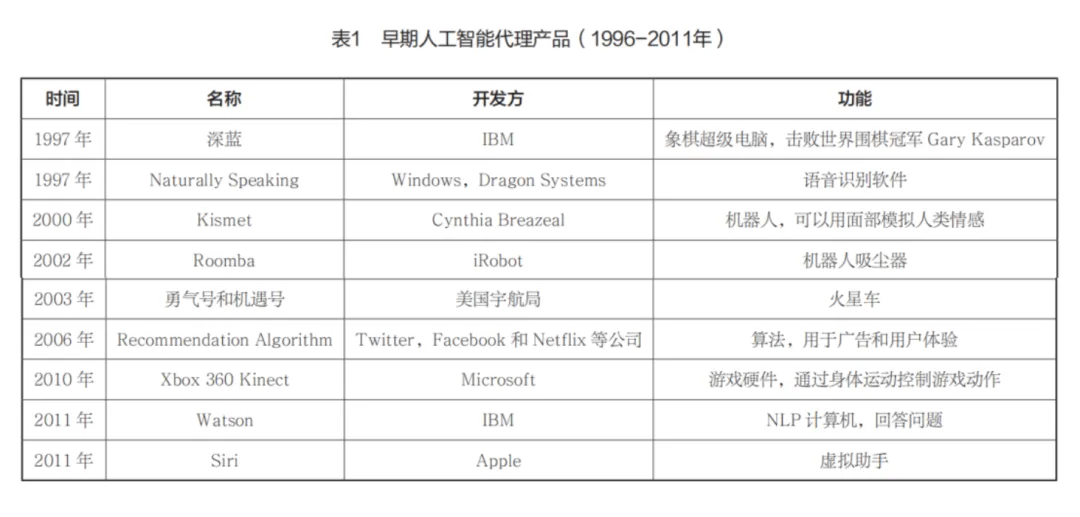
1997年,由IBM开发的超级电脑“深蓝”(Deep Blue)击败世界围棋冠军加里·卡斯帕罗夫(Gary Kasparov),成为首台在“人机对战”中战胜人类象棋冠军的机器。“深蓝”的对弈决策在通用超级计算机处理器和480颗特制的VLSI象棋加速器芯片的支持下完成,前者的软件只执行部分象棋运算,后者则处理更复杂的棋步。尽管后来遭到质疑的IBM拒绝与卡斯帕罗夫再战,但人工智能也已经能够在“有完全信息的组合游戏”中击败人类。根据“摩尔定律”(Moore’s law),计算机芯片的性能平均每隔18个月就会翻一番,与之并驾齐驱的是突飞猛进的计算机软件。由此可以推论,由软硬件驱动的人工智能将会不断进化。的确,尽管“深蓝”已经被IBM大卸八块,其后的人工智能代理产品却推陈出新,且功能逐渐分化,拓展至算法推荐、智能家居、虚拟助手、航空航天等领域(见表1)。
(三)涌现期(2012年以来):功能通用化
然而,在“深蓝”之后的近20年内,暴力搜索法、Alpha-beta剪枝、启发式搜索等传统的人工智能方法在面对组合可能性更多的围棋游戏时都显得无能为力。直到2015年左右,Google DeepMind才扭转了这一僵局,其利用强化学习(reinforcement learning)技术训练的人工智能围棋系统AlphaGo于2016年3月以4:1的总比分击败了曾经14次荣膺世界冠军的韩国职业九段棋手李世石。然而,虽说AlphaGo在围棋、国际象棋、日本象棋等棋类游戏中的表现震撼人心,但它却只能做下棋这一件事,既不能玩转任何其他游戏,也无法完成现实生活中的简单任务。所以,人类对AlphaGo的集体焦虑很快就消退了,因为下棋下得好并不需要通用智能。人工智能先驱之一约翰·麦卡锡(John McCarthy)精准地概括了人工智能发展的一个困境:“一旦它开始奏效,就没人再称它为人工智能了。”也就是说,人工智能存在移动的球门柱:当计算机在某一特定任务上超越人类时,我们就得出结论,该任务实际上并不需要智能。
对通用人工智能孜孜以求的科学家与工程师们不甘心将对人工智能代理的想象与探索止步于此,他们期待将《机器人瓦力》(Wall-E)、《星球大战》(Star Wars)、《头号玩家》(Ready Player One)等科幻作品变为现实,创造出充满好奇心、能够进行终身学习的通用人工智能代理。在计算机软硬件的支持下,人工智能领域在神经网络(neuralnet work)、机器学习(machine learning)、大数据(big data)等方向取得新突破,一系列更为普遍的人工智能成果开始在我们身边悄然出现。从IBM的深蓝到沃森(Watson)再到AlphaGo,统称为“深度学习”(deep learning)的人工智能方法已经成了主流的人工智能范式,开始在计算机视觉、语言、翻译、预测、生成和无数其他问题上显示出明显优于其他方法的优势。到21世纪第二个10年,基于大语言模型的方法在语义理解与表达方面实现突破,掀起一波以ChatGPT为代表的生成式人工智能浪潮。2023年以来,Camel(3月21日)、AutoGPT(3月30日)、BabyAGI(4月3日)、Voyager(5月27日)等多个人工智能代理如雨后春笋般面世。不同于只能玩棋类游戏的AlphaGo,这些由大语言模型驱动的生成式智能代理被设计为能够适应跨游戏环境、自主学习游戏技能、自由探索游戏玩法的“玩家”。比如,2023年5月25日,商汤科技联合清华大学、上海人工智能实验室等机构发布的GITM(Ghost in the Minecraft)能够玩转《我的世界》(Minecraft);Google Deep Mind于2024年3月14日推出的SIMA(Scalable Instructable Multiworld Agent)在《无人天空》(No Man’s Sky)、《拆迁》(Teardown)、《英灵神殿》(Valheim)和《模拟山羊3》(GoatSimulator 3)等9款游戏中都进行了训练与测试。
如今,在以GPT平台(GPT Platform)为核心的开发环境支持下,通用化的人工智能代理还在持续涌现。GPT(生成式预训练转换器)是机器学习模型的核心架构,为ChatGPT等大语言模型(LLM)提供动力。而代理虽然也是一种大语言模型,但需要将其设置为在确定某些目标/任务的情况下反复运行。这与大语言模型在ChatGPT等工具中的“通常”使用方式不同。在这种工具中,用户提出一个问题,得到一个单独的响应作为答案。而代理具有复杂的工作流程,模型基本上是在没有人强制干预的情况下进行自我对话。随着时间的推移,代理将在更强大的模型和工具的支持下变得越来越复杂,从而在未来化身为由通用人工智能驱动、可以解决众多任务的实体。
四、前沿趋势:生成式人工智能代理
前述围绕人工智能代理展开的人工智能简史讲述了人工智能的理念落地与进化历程,当前的人工智能代理热潮则是大模型驱动下通用人工智能(Artificial General Intelligence,AGI)发展的阶段性成果,涌现于人工智能领域的平台化进程之中。
(一)拟真式环境:游戏版真实世界
如上文所述,尽管深蓝与AlphaGo等人工智能产品已经展现出令人震撼的卓越能力,但它们仍然不符合科学家关于智能代理的未来想象——它们还不能“像人类一样生存、探索和创造”。为了实现这一终极目标,研究者们延承了始于20世纪70年代的拟真实验技术路线,即令人工智能代理在拟真式环境中进行交互式学习,从而提高解决通用问题的能力。1972年,为了将问题的复杂性降到可管理的程度,计算机博士特里·威诺格拉德(Terry Winograd)搭建了一个模拟空间,其中包含了许多彩色物体(方块、盒子和锥体),名为SHRDLU的虚拟机器人可以根据用户的指令来排列对象,也可以使用模拟机械手臂来操作对象。人和机器人之间的交流通过键盘进行,机器人的回复出现于屏幕底部。SHRDLU可以进行关于虚拟世界的对话,也可以制订及执行行动计划,甚至还可以回答有关自身动机的问题——巧妙地“展示”(demo)了人类通过发出指令让机器人在特定环境中工作的场景。至20世纪80年代,源自麻省理工学院媒体实验室的“展示不了就去死”(demo or die)文化在人工智能圈盛行开来。秉持这种实验室精神,在尚难以直接将智能代理嵌入真实世界的情况下,人工智能代理研究亦采取了先在拟真式虚拟环境中测试,再转向现实物理世界的技术路线。
那么,如何为人工智能代理搭建一个拟真式实验环境呢?当前,培育人工智能代理的“实验室”主要包括两类——现成的游戏平台与后建的测试平台。在现成的游戏平台中,最受欢迎的莫过于微软旗下游戏公司Mojang Studios开发的沙盒类游戏《我的世界》,从美国的DeepMind、OpenAI到国内的商汤科技、清华大学、北京大学等,研究团队利用该游戏开展人工智能代理训练。《我的世界》备受青睐的原因不难理解。首先,它仿佛一个缩小版的现实世界,为研究人员提供了一个观察人工智能代理对复杂环境适应性的模拟实验室;人工智能代理身处由随机程序生成的形态各异的游戏环境中,可以通过使用原始的机械设备、电路、逻辑门以及内置于游戏的材料“红石块”来构建更为复杂的机械,在相互协作与竞争中完成生存、探索和创造等各类复杂的社会性活动。其次,人类玩家的对局数据被“投喂”给大模型,为其训练提供了丰富的“学习资料”。此外,《我的世界》代码相对简单,容易接入,便于研究团队利用现有资源搭建新的测试环境。当然,与其他实验方式相比,拟真游戏环境成本更低、安全系数更高,亦促使其成为“从0到1”的探索性研究的不二之选。
除了利用现成的游戏平台,亦有研究团队选择利用来自真实世界的环境数据搭建虚拟环境,比如来自香港大学的Jihan Yang和纽约大学的谢赛宁等人通过APIs接入数字地图、街景图像等多种已成型的地理信息软件或平台,调用现有的环境数据与应用界面,为人工智能代理创造了更加接近现实世界的、可扩展的平台——V-IRL,由此,人工智能代理在多个地理信息软件“交互”而成的虚拟空间中完成探索性任务,如同被嵌入地球的真实城市街巷之中。
(二)交互式学习:社会化智能主体
按照主流智能理论,人工智能代理不仅需要在与环境交互过程中利用工具、规划任务以解决问题,还应当掌握与其他人工智能代理及人类交互协作的能力,因而研究者在探索阶段往往给予其“交互式”的工作任务,测试与提升人工智能代理的协作能力及协助人类活动的能力。“交互式学习”包括两层含义。其一,人工智能代理与不确定的环境进行交互,并从中掌握处理非线性任务的技能。其二,人工智能代理间交互、人机交互等多主体互动模式,从根本上模拟了人类社会的运作机制——劳动分工,致力于使智能主体的行动更具“社会化”特征。
一方面,人工智能代理不是只能线性执行人类给出的程序指令的机器,而是在大语言模型的统筹指挥下开展自主探索活动,其学习过程具有非线性、创造性和灵活性特征。比如,英伟达的Jim Fan团队在向大语言模型下达“尽可能多地用各种工具挖矿”的总目标,再针对基本规则与动作进行提示后,将人工智能代理Voyager“扔”进《我的世界》中。在大语言模型的驱动下,Voyager针对最终目标生成细分任务,通过对世界环境的观察和交互了解各种操作的效果,将正向操作(如用斧子砍树比用手刨快)存储于短期记忆之中,不断优化自身的子目标,最终实现“挖矿”的总目标。在这种情境下,Voyager并未遵循预设的程序与算法执行确定的任务,而是在充满不确定性的未知环境中“因地制宜”地采取多元化的行动策略,“无师自通”地掌握了挖掘、建房屋、收集、打猎等技能。
另一方面,参照人类的行动交往模式,人工智能代理不仅需要完成“单打独斗”式的任务,还应能参与团队行动,因此除了单一代理(single agent),多代理(agent-agent)、混合代理(agent-human)亦成为目前研究的重要类型。多智能代理间协作的模式主要包括两种。一是任务分配不均的双代理模式,其前提在于假设现实社会存在大量a辅助b的任务执行情况。二是任务分配均匀的多代理模式和人类-代理人协作模式,其前提在于假设责任平等。作为一种用于新兴游戏交互的基础设施,MindAgent支持多NPC(Non-Player Character,指游戏中的非玩家角色)协作和人类NPC协作,较全面地涵盖了多智能代理间协作模式。它以多人合作模拟厨房游戏《分手厨房》(Overcooked)为参照,通过简化游戏的部分复杂操作,为人工智能代理搭建了新的支持人工智能代理间协作、人机协作以及VR交互的游戏场景CuisineWorld,作为玩家的多个人工智能代理须在规定时间内合作完成各种菜品的制作并送到顾客手中。
实际上,早在1986年,美国人工智能科学家马文·明斯基(Marvin Minsky)就在其著作《心智社会》(Society of Mind)中设想过人工智能代理的交互模式——智力是由许多具有特定功能的较小主体的相互作用产生的,这一新颖的智力理论不失为当前多人工智能代理协作模式的一种前瞻性预测。
(三)生成式智能:通用人工智能之路
有趣的是,人工智能代理的应用场景已经覆盖机器人、游戏、虚拟助理、自动驾驶等细分领域,然而其技术功能却始终未超出尼葛洛庞帝的电子“管家”设想,只不过媒介形态从内置于计算机的软件程序拓展至各类物理实体。例如,瑞典大型金融科技公司Klarna表示,由OpenAI提供支持的AI助手在短短一个月内承担了700名全职客服的工作,完成了230万次对话,其客户满意程度“与人工客服人员相当”。人工智能初创公司Rabbit在2024年CES(美国拉斯维加斯消费电子展)上展出了一款主打语音交互功能的AI产品Rabbit R1,这款智能助手形似缩小版的手机,却不内含应用程序,能够在GPT-4和其他大模型的驱动下理解人的语音内容,模仿人使用软件的方式自动完成点外卖、听音乐、软件叫车等任务,仿佛一台人与智能手机之间的智能对讲机。
这类被称为智能助手(AI Assistant)的人工智能代理在社会生产生活中担任替代或者优化部分人类劳动的“秘书”,而面向组织的人工智能代理则更像一个能够通过分工协作自行解决问题的合作团队。比如,人工智能实验室Cognition Labs于2024年3月12日推出世界上“第一位AI软件工程师”,充分展现多代理协作。这个名为“Devin”的人工智能代理产品被设计为一个软件团队,它不再像GitHub Copilot等编程AI助手那样扮演程序员的“副驾驶”角色,而是在接收任务指令后自行进行方案规划、需求创建和任务分配,创建出更多小型AI助手,它们在各自的沙盒终端、代码编辑器和浏览器之间穿梭以完成特定任务。整个团队经过持续测试、调试并迭代,直至创建出完整的应用程序供用户检查并请求更改。
从这些简略的描述即可窥见,新一波人工智能代理热潮的核心关键词为“通用”。与受控于预先确定的参数、只能完成单一任务的人工智能相比,通用人工智能的目标是完成规定参数之外的任务。所谓的“通用”指的是人工智能面对不确定性环境处理多个任务的自学能力。可见,不同于由确定的计算机程序控制的NPC,生成式人工智能代理不受固定的动作参数限制,而是探索限定动作之外的多元“玩法”,更接近通用人工智能的设想。
那么,人工智能代理的“通用”潜质从何而来?近年来,大语言模型的突破性进展表现为ChatGPT、Midjourney、Runway、Pika等原生AI应用的流行,但是这些模型不仅具有文案、图片和视频的生成以及学习、体验与搜索的优化功能,还被研究者视为通用问题求解器。在此背景下涌现的GITM等人工智能代理代表了智能代理研究范式转型的实践成果——人工智能代理突破了强化学习的传统技术架构,转向以大语言模型为智能驱动力的新范式。此前,强化学习式人工智能代理面临的难题在于如何将极为复杂的任务映射到最底层的键盘鼠标操作。与之相比,生成式人工智能模型利用海量数据集进行训练,能够使用类似于人类创作的文本、音频或视觉效果来响应人类查询;同时,大语言模型还具备量级巨大的知识库和紧急零样本规划能力,能够将自然语言指令分解为一系列子任务,再使用低级控制器执行子任务,逐步将复杂任务分解为子任务、结构化动作,直到最底层的键盘鼠标操作。围绕人工智能代理展开的游戏化训练与商业化应用本质上受制于大语言模型处理文本、统筹规划的能力,实验环境运转的前提是对拥有庞大知识库、具备紧急零样本规划能力的大语言模型的稳定接入;而生成于拟真训练过程的数据资源最终也将“反哺”大语言模型的改进与迭代,进一步扩充其量级巨大的知识库,提升其语言处理、任务分配与主体调度的灵活度和创造力。
不过,大语言模型的幻觉问题依然难以解决,人们发现以“命令-执行”的线性方式来要求大语言模型输出答案常常并不奏效。实际上,人工智能代理的技术理念最终要回归作为技术设计者与使用者的人本身——研发者通过调整“提示”(prompt)来调用大语言模型,激发后者未被利用的技术实力,以构建符合自身需求的定制版人工智能代理。
五、余论:平台化渗透人工智能市场
行文至此,人工智能代理起源与发展的历史脉络已然浮现。对人工智能代理的媒介考古表明,盛行于各个时段的人工智能代理项目,都曾是当时人工智能领域核心范式的实体化产物。当然,任何由商业力量推动的技术浪潮都难以避免炒作色彩,同时也反映出阶段性的科技趋势与市场形势。因此,我们暂且搁置2023年以来被冠以“智能体”的技术热潮是否可能化为泡沫的预测,而是将其视为生成式人工智能技术实体化的产物,讨论其何以形成,以及如何带动市场资源的流动与市场关系的整合。
新一轮人工智能代理热潮的技术路线以大语言模型为范式,游戏测试本质上是为了测试和提高大语言模型的多智能代理规划能力,即为多个人工智能代理制定协作计划、避免发生冲突的能力;而各大科技公司纷纷推出的人工智能代理商业应用也无非是大语言模型应用的变体,对接的是科技行业的变现需求,即将消耗巨大算力资源的大模型落地为创收项目。
大语言模型驱动的人工智能代理被视为下一代平台的前提在于智能代理根植于以算力资源为核心的基础设施网络,而后者早已呈现不可逆转的平台化趋势。也就是说,任何个人或组织想“定制”自己的人工智能代理,都无法脱离由各种外部工具构成的复杂基础设施环境,而这一可编程的智能代理开发环境本就由平台公司及其合作伙伴搭建。
首先,在政治经济转型(金融化和放松管制)的宏观影响和网络效应、数据驱动等独特因素的塑造下,网络计算资源从传统垄断基础设施模式转向平台化基础设施模式,呈现出鲜明的私有化与分裂化趋势。在“基础设施即服务”(Infrastructure as a Service,IaaS)模式下,任何算力资源都能被转变为服务提供给不同用户(包括企业、科研机构、个人用户等),企业无须购买包括软件、硬件等在内的复杂架构的产品并在现场安装以创建网络,只需为自己所需的特定服务付费,从而极大地节省成本与盘活资源。算力资源基础设施的私有化与分裂化也意味着,算力资源持有者构成相互牵制的关系网络,任何技术力量都无法独立运行。比如,掌握有限算力资源的OpenAI等新锐巨头通过向第三方租借GPT-4等基础设施型资源形成在大语言模型乃至人工智能领域的优势地位;而OpenAI的ChatGPT亦非独立存在的技术产品,其采取向微软、谷歌、英伟达等老牌科技巨头租用芯片、云服务的算力租赁方式完成复杂的训练与运行过程,因而人工智能代理的发展亦可能进一步强化微软、英伟达等老牌巨头在科技行业的垄断地位。其中,支撑GPT服务的硬件设备主要是芯片及搭载芯片的数千台服务器和数百个标准机柜。根据英伟达估算,训练一个ChatGPT-175B大模型需使用1,024块A100芯片,即128台8卡A100服务器,硬件采购成本就高达1.54亿元人民币。囿于高昂的硬件采买成本,OpenAI及其他中小企业便采取算力租赁方式进行大模型训练,以控制成本。在云服务一侧,受微软注入资本影响,ChatGPT的合作伙伴从谷歌云服务平台转向微软的Azure平台,但仍然消耗巨大的成本。可以说,具备算力与资本优势的微软等老牌科技巨头以出租云服务、注入资本等方式布局人工智能领域,成为人工智能平台市场的底座式玩家。
其次,老牌巨头的触角不仅抵达ChatGPT背后的OpenAI,还零散分布于游戏等细分市场之中——此前较少被关注的“游戏即平台”模式随着人工智能代理训练的流行而浮出水面。《我的世界》等游戏之所以在人工智能代理热潮中扮演模拟实验室角色,是因为其商业模式越来越趋近于平台模式,作为第三方的研究人员可以通过租赁服务、API接口接入游戏环境,根据自身需要搭建新的基础设施环境。《我的世界》自2009年诞生起便被描述为一个“平台”,但其含义更多指向“社区”,即强调业余粉丝玩家对游戏演进的共同参与,与“平台资本主义”的定义相去甚远。近年来,杰弗里·帕克(Geoffrey Parker)等人提出的数据驱动的“网络效应”逐渐凸显于该游戏的发展历程中,起因是《我的世界》于2014年被微软收购,至今已拥有3亿销量与1.5亿月活跃用户,成为全球有史以来最畅销的视频游戏,储备了庞大的用户数据。学者大卫·墨菲(David Murphy)指出,《我的世界》仿佛游戏界的Facebook和Google,在过去10年的发展过程中建立了游戏史上前所未有的用户规模基础,从一种实验性的、令人惊讶的社交游戏转变为“游戏即平台”的商业模式,已化身为基础设施型平台。
最后,对于提供算力资源服务的平台公司来说,可继续编写或重新组装的Web应用框架是其提供给“用户”的产品之一。这些软件应用程序既不相互独立,也不紧密联结,而是呈现模块化状态。作为“用户”的程序员利用像“钩子”一样的应用程序接口(Application Programming Interface,API)将像“模块”一样的软件应用程序组装成新的软件产品,节省了从头编写或构建软件的成本。所谓的API实际上是一组编程代码,是软件间通信与数据交换的媒介,支持软件系统(例如数字平台)之间的编程通信以及数据和功能交换,并作为核心基础设施元素为第三方和合作伙伴创建的应用程序和服务保驾护航。随着平台商业模式的崛起,平台研究学者通过追溯Google和Facebook等的平台演化历程,认识到平台公司在当今社会的“数据主导地位”与API在数字基础设施中的核心地位,指出API业已成为“主宰数字世界”的一种方式。也就是说,利用API与第三方共享数据或集成服务成为平台商业模式的核心技术环节。通过API接入平台现成资源的“第三方”开发人员基于自身的创造性需求,在平台的核心基础设施之上搭建新的应用场景,生成新的技术产品或服务;与此同时,平台本身也在这些外部力量的共同参与下不断演化,通过控制“接口使用”的标准化以维持自身稳定性。API的工作原理如图1所示。
与传统的信息通信公司相比,平台公司的经济和组织特性表现为“可编程性”(programmability),即通过将“用户”(包括但不限于非营利组织、政府、企业、内容开发商和广告商)聚集在一起运营“多边市场”,其功能在于促成用户间的交互与交易,仿佛一个容纳多元主体的“生态系统”。曾经主导基础设施的“系统构建者”可能要让位于“生态系统构建者”,后者不是靠直接提供资源而是利用可编程性和互联互通来实现控制。谁将成为新的“生态系统构建者”?现在给出定论还为时过早,但到热潮退却的那一天,这将是科技行业面临的核心问题。
(注释略)
作者胡泳系北京大学新闻与传播学院教授、博士生导师;张文杰系北京大学新闻与传播学院2023级博士研究生。本文原载于《现代出版》

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}