04
幻觉,抑或虚构
之所以认定GPT无法成为谷歌搜索的替代物是因为,如果GPT以很高的信心给出错误的答案,它又怎么会取代谷歌呢?例如,有用户要求ChatGPT给出一份关于社会认知理论的顶级书单。在回答的10本书中,4本书不存在,3本书是由不同的人写的。当谷歌技术与社会高级副总裁詹姆斯·曼尼卡(James Manyika)在一个演示中向Bard询问通货膨胀问题时,聊天机器人推荐了五本不存在但听起来可能存在的书,比如彼得·特明(Peter Temin)的《通货膨胀战争:现代史》。特明是一位确实存在的麻省理工学院经济学家,研究通货膨胀,并写过几本书,只是其中完全没有被推荐的那本书。
人工智能研究人员有个说法,AI系统会频繁地产生“幻觉”(hallucination), 即编造与现实无关的事实。技术分析师本尼迪克特·埃文斯(Benedict Evans)将ChatGPT描述为 “一个自信的扯淡的家伙,可以写出非常有说服力的废话”。
就聊天机器人而言,幻觉指的是原本正确的回答中加入不正确的信息。必应机器人会把错误的信息当作事实同正确的数据一起呈现,使人难以分辨出真实的陈述与错误的陈述。例如,必应可能并不知道某个与财务数据有关的数字,但它会编造一个,然后将这个数字与其他正确的信息一起呈现。当一家媒体要求ChatGPT为特斯拉撰写季度收益报告时,它吐出了一篇措辞流畅的文章,没有语法错误或逻辑混乱,但它也插入了一组随机的数字,与任何真正的特斯拉报告都不相一致。没有迹象表明其内部意识到这些数字是机器人自己想象的产物。

在人工智能中,类似的现象都被称为“幻觉”,是指人工智能做出的并不符合其训练数据的自信反应。它与人类心理学中的幻觉现象相类似,但请注意,人类的幻觉是人类的一种感知,它不能理智地与人类目前直接用感觉器官观察到的那部分外部世界联系起来,而人工智能的幻觉则是人工智能的自信反应,它无法在人工智能曾经访问或训练过的任何数据中立足。
2022年左右,随着某些大型语言模型的推出,人工智能的幻觉被凸显出来。用户抱怨说,聊天机器人似乎经常“反社会”,毫无意义地在其生成的内容中嵌入似是而非的随机假话。到2023年,分析师认为频繁的幻觉是LLM技术的一个主要问题。它可能会产生有害的后果,因为没有足够领域知识(domain knowledge)的用户开始过度依赖这些似乎越来越有说服力的语言模型。
然而,随着该话题成为主流,这个标签的争议也越来越大,因为有人觉得它将人工智能模型拟人化(即暗示它们有类似人类的特征),或者赋予这些模型并不存在的能动性(即暗示它们可以作出自己的选择)。一些批判性人工智能研究者明确表示反对使用幻觉一词,因为它将算法输出与人类心理处理混为一谈。在回应Meta公司关于其模型Galactica的免责声明时,语言学家埃米莉·本德(Emily M. Bender)写道:“让我们反思一下他们的免责声明的措辞,好吗?‘幻觉’在这里是一个糟糕的选词,它暗示语言模型具有*经验*,并且可以*感知事物*。(此外,它还在轻描淡写地描述一种严重的精神疾病的症状)。同样,人们还称‘语言模型往往是自信的’。不,它们不是这样的,因为这需要主观的情感。”
商业LLM的创造者也可能利用幻觉作为借口,将错误的输出归咎于AI模型,而不是对输出本身负责。例如,谷歌DeepMind的一篇会议论文《语言模型所带来的风险分类》明确表示:“语言模型的训练是为了预测话语的可能性。一个句子是否可能,并不能可靠地表明该句子是否也正确。”
在此情况下,有研究者主张使用“虚构症”(confabulation)或“虚言症”一词来描述相关现象,虽然也不尽完美,但对照“幻觉”是一个更好的隐喻。在心理学中,当某人的记忆出现空白,而大脑在无意欺骗他人的情况下令人信服地填补了其余部分时,就会出现“虚构”。 一般来说,“虚构症”患者编造出听起来很有道理的理由,但却没有任何事实依据。这通常不是有意识的欺骗行为,而是真的相信他们报告的故事。这种行为与LLM的做法十分相同。
在过去数月里,像ChatGPT这样的人工智能聊天机器人已经吸引了全世界的注意力,因为它们能够以类似人类的方式就几乎任何话题进行交谈。但它们也有一个严重的缺点:可以轻易地提供令人信服的虚假信息,使之成为不可靠的信息来源和潜在的诽谤策源地。
在2021年的一篇论文中,来自牛津大学和OpenAI的三位研究人员确定了像ChatGPT这样的LLM可能产生的两大类虚假信息。第一种来自于其训练数据集中不准确的源材料,如常见的错误概念。第二种情况来自于对其训练材料(数据集)中不存在的特定情况的推断;这即属于前述的“幻觉”,或者“虚构”。
在ChatGPT推出后不久,人们就开始宣称搜索引擎的终结。但与此同时,许多关于ChatGPT“虚构”的例子也开始在社交媒体上广为流传。这个人工智能机器人发明了不存在的书籍和研究报告,教授从未写过的出版物,假的学术论文,伪造的法律引用,子虚乌有的报刊文章,真实人物传记的编造细节,危险的医疗建议,等等,不一而足。
然而,尽管ChatGPT喜欢随便撒谎,但违反直觉的是,它对“虚构”的抵抗能力也是我们今天持续谈论它的原因。ChatGPT始终处于不断改进之中,它现在会拒绝回答一些问题,或让你知道它的答案可能不准确。必应聊天机器人在更新了版本之后,一方面大大减少了无缘无故拒绝回答的情况,另一方面,回答中出现“幻觉”的情况也减少了。
但本质上,GPT模型的原始数据集当中并不存在任何东西能够将事实与虚构分开。理解ChatGPT的虚构能力的关键是理解它作为预测机器的作用。当ChatGPT虚构时,它其实在寻找其数据集中不存在的信息或分析,并用听起来合理的词来填补空白。由于ChatGPT拥有超人的数据量,所以它特别善于编造事情,而且它蒐辑单词上下文的能力非常好,这有助于它将错误的信息无缝地放入周遭的文本中。
GPT模型是否会进行疯狂的猜测,是基于人工智能研究人员称之为“温度”的属性,它通常被描述为有关“创造力”的设置。如果创造力设置较高,模型就会胡乱猜测;如果设置较低,它就会根据其数据集确定性地吐出数据。因此,微软广告和网络服务部首席执行官米哈伊尔·帕拉金(Mikhail Parakhin)在推特上讨论必应聊天机器人产生幻觉的原因时指出:“这就是我之前试图解释的:幻觉=创造力。它试图利用所有可支配的数据来生成字符串的最高概率的延续。很多时候它是正确的。有时人们从未生成这样的延续。”
而那些疯狂的创造性跳跃是使大型语言模型变得有趣的原因。“你可以钳制幻觉,但它会变得超级无聊。它总是回答‘我不知道’,或者只是读取搜索结果中存在的内容(而那些内容有时也不正确)。此处缺失的是说话的语气:在这类情况下,它不应该听起来那么自信。”
另外还有压缩的问题。在训练过程中,GPT-3考虑了PB级别的信息,但所产生的神经网络在大小上只是如此庞大的信息的一小部分。在一篇被广泛阅读的《纽约客》文章中,小说家特德·姜(Ted Chiang)称ChatGPT只是“万维网的一张模糊图片”。这意味着很大一部分事实性的训练数据被丢失了,但GPT-3通过学习概念之间的关系来弥补,之后重新制定这些事实的新排列组合。就好比一个记忆力有缺陷的人凭着对某件事情的直觉而工作一样,它有时会把事情弄错。也因此,即使它不知道答案,也会给出它最好的猜测。
我们同样不能忘记提示(prompt)在虚构中的作用。在某些方面,ChatGPT是一面镜子:你给它什么,它就回给你什么。假如你给它提供虚假的信息,它就会倾向于同意你的观点,并沿着这些思路“思考”。这就是为什么在改变主题或遭遇不想要的回应时,用新的提示开始是很重要的。而ChatGPT是概率性的,这意味着它在本质上是部分随机的。即使是相同的提示,它的输出结果也会在不同时段发生变化。
在对ChatGPT这样的语言模型进行微调时,如何平衡创造力和准确性是一大挑战。一方面,作出创造性反应的能力使ChatGPT成为产生新想法或打破创意窒碍的强大工具。这也使语言模型变得更像人。另一方面,当涉及到产生可靠的信息和避免虚构时,原始材料的准确性是至关重要的。在这两者之间找到适当的平衡是语言模型发展的一个持续的挑战,然而这一过程是产生一个既有用又值得信赖的工具所必须的。
05
伊莱扎效应及其后果
由于以上的原因,ChatGPT不能可靠地取代维基百科或传统搜索引擎(这并不是说维基百科或搜索引擎就完全准确)。正如特德·姜在其优雅的分析中所显示的,要构成一个值得信赖的搜索替代品,LLM需要在高质量的数据上进行训练,并避免“彻底的捏造”。当谷歌发布其新的聊天机器人Bard时,不知为何忽略了对演示中显示的错误内容进行事实核查,这一奇怪的失败使该公司蒙受了千亿美元市值损失,似乎成为姜的论点的最好注脚。
所有这些都导致了一个结论,一个OpenAI自己也同意的结论:目前设计的ChatGPT并不是一个可靠的事实信息来源,因此我们并不能信任它。它不是为了成为事实而建立的,因此不会成为事实。将它整合到搜索引擎中几乎肯定会提供虚假信息。然而我们有另一种思考幻觉的方式:如果目标是产生一个正确的答案,比如一个更好的搜索引擎,那么幻觉是必须加以摒弃的。但从另外的角度来看,幻觉是一种创造。所以,提供准确信息不在行,并不意味着它不是一个可行的消费者业务,只要在这条路上走得足够远,一些公司会想出办法,把辛迪妮从聊天框里放出来,带到市场上(但不一定是微软或谷歌)。
ChatGPT扩大了能够利用人工智能语言工具的人的范围。该系统向用户呈现一个熟悉的界面,可以像人一样与之互动,其界面的成功现在为设计师创造了一个崭新的挑战。所有来自象牙塔外的人与类似的工具互动,这固然很好,但设计师面临的任务是,如何真正向人们传达这个模型能做什么和不能做什么。
人工智能创业公司的首席执行官宾杜·雷迪(Bindu Reddy)预见到这样一个时代:像ChatGPT这样的工具不仅有用,而且有足够的说服力来提供某种形式的陪伴。“它有可能成为一个伟大的治疗师。”
ChatGPT产生的这类反应让我们想起迎接ELIZA(伊莱扎)的狂热。ELIZA是20世纪60年代的一个开创性的聊天机器人,它采用了心理治疗的语言,对用户的询问产生了似是而非的回应。为此,ELIZA的开发者、麻省理工学院的计算机科学家约瑟夫·魏岑鲍姆(Joseph Weizenbaum)“感到震惊”,人们与他的小实验进行互动,仿佛它是一个真正的心理治疗师。在魏岑鲍姆关于伊莱扎的论文发表后,没过多久,一些人(包括一些执业的精神科医生)开始说,如果一台机器可以做这种事情,谁还需要心理治疗师?

这就仿佛今天的教育家和艺术家对当代生成式人工智能工具的狂热一样。因为GPT-3/4能产生令人信服的推文、博文和计算机代码,我们于是在这个数字系统中读出了人性——并且对它的局限不太在意。此即“伊莱扎效应”(Eliza Effect),当有人错误地将人类的思维过程和情感归于人工智能系统,从而高估了该系统的整体智能时,就会出现伊莱扎效应——如果从1966年1月魏岑鲍姆推出ELIZA的时刻算起,它已经愚弄了我们半个多世纪了。
虽然这种现象似乎让人想起《她》和《机械姬》(Ex Machina)这样的科幻电影,但并不需要高度复杂的人工智能来触发伊莱扎效应。站在今天的位置回看,ELIZA是相当初级的聊天机器人,它并没有从文本中学习,仅仅根据其设计者定义的一些基本规则运作。它几乎是重复别人对它说的任何话,只是以简单的短语或问题的形式。然而即便如此,许多人仍然把它当作人类一样对待,毫无保留地卸下他们的问题,并从回答中获得安慰。
魏岑鲍姆编写这个程序是为了表明,虽然机器表面上可以复制人类的行为,但它实际上就像魔术师从帽子里拿出一只兔子,只是一种幻觉。而一旦你知道这个把戏是如何完成的,魏岑鲍姆认为,它就不再是一个幻觉了。所以,令他大吃一惊的地方在于,哪怕人们知道ELIZA只是一个程序,他们似乎也会认真对待它。
ELIZA在心理治疗方面没有任何专业培训或特殊编程。事实上,它什么都不知道。但它的通用文本输出通过反映用户的语言来模拟理解。仅凭做到这一点,用户就开始对它的反应赋予更多的意义。参与者开始感觉到,在他所创建的这个相对简单的、基于规则的工具背后有一个巨大的智能。尽管参与者被告知ELIZA是一台机器,但他们仍然对魏岑鲍姆所说的“概念框架”或某种心智理论具有强烈的感觉,甚至是了解计算机科学的人,最后也会产生一种幻觉,以至于他们会说希望自己能够私下里同机器说话。
魏岑鲍姆在用户身上一次又一次地看到这种行为。人们很乐意向ELIZA透露他们生活中的私密细节,而ELIZA则会以一种哄骗他们继续的方式作出回应。在随后的几年里,魏岑鲍姆逐渐成为他曾经倡导和帮助建立的技术的最大声的批评者之一。他将自己的创造描述为“骗局”和“打造幻觉的机器”。他更广泛地抨击了机器和人类思维之间的界限被侵蚀的状态,呼吁划出一条“界线”,“将人类与机器智能分开",由此变成人工智能的技术决定论的终生反对者。
幻觉的市场,比事实和真相大得多。如果你觉得你的语音助手有自己的个性,或者在与ChatGPT对话时出现一种亲情的感觉,你很可能已经落入了伊莱扎效应。也许最有名的是布雷克·莱莫因(Blake Lemoine)事件,他是谷歌的前人工智能工程师,公开宣称该公司的大型语言模型LaMDA已经活了。
2023年1月,微软在一篇宣布同OpenAI扩大合作关系的博文中说,它计划投资部署专门的超级计算系统,以加速OpenAI的人工智能研究,并将OpenAI的人工智能系统与它的产品相结合,同时“引入新类别的数字体验”。或许我们可以说,那种新的数字体验,就是幻觉,也即伊莱扎效应的体现。
伊莱扎效应缘于魏岑鲍姆的工作,他是美国第一批人工智能研究者之一。早在20世纪50年代,他就探索了使计算机更复杂和更像人类的方法,通过编程使其执行与感知和推理等相关的任务。这最终导致了突破性的计算机程序,可以解决文字问题,证明逻辑定理,甚至玩跳棋。
然而,有一个领域是魏岑鲍姆未能用计算机完全征服的:人类语言的理解和创造。在人工智能的世界里,这被称为自然语言处理。计算机在彼时仍然无法与人类进行有说服力的、流畅的对话,因为理解和表达语言的工作是如此复杂和细微,对于20世纪的计算机来说,过于复杂和细微了,除非对话被非常严格地限制在与特定主题相关的固定问题和答案上。
然而,随着机器学习和深度学习等人工智能子领域因应互联网(及其产生的海量数据)的兴起而不断发展,计算机现在已经足够灵活,可以自行学习——甚至生成——自然语言。通过使用神经网络分析大量在线语言,现代 AI 模型的学习速度远快于一次一步编程的学习速度。随着对话式人工智能在客户服务、市场营销、机器翻译、情感分析、虚拟人工智能辅助等领域的应用不断增加,可能会越来越难以辨别交流另一端的实体是否是人类。而莱莫因、鲁斯、汤普森和其他人报告的感受可能会随着更复杂的聊天机器人进入市场而变得更加普遍,特别是由于OpenAI正在继续追求通用人工智能(Artificial general intelligence, AGI)。
虽然伊莱扎效应允许人们以更细微的方式与技术打交道,但这种现象确实带来了不可忽视的负面影响。首先,高估人工智能系统的智力可能导致过度的信任,当这样的系统出错时,这可能是相当危险的。此前,我们已经看到用户不加批判地信任搜索结果,而自然语言交互会使这种信任更加明显。
其次,随着此种技术和其他技术的不断改进,它们可以被用来在互联网上以前所未有的规模向轻率信任的消费者传播虚假信息。眼下,ChatGPT和其他复杂的聊天机器人经常放出虚假信息。但这些信息被包装成了雄辩的、貌似正确的声明,以至于人们很容易把它当作真理来接受。当用户已经在把将高水平的智能和对现实世界的理解归于AI系统时,这必然会成为一个大问题。
再次,除了普通的虚假信息和错误信息之外,伊莱扎效应还可以成为一种非常强大的说服手段。如果有人将大量的智慧和事实归因于特定的聊天机器人,他们就更有可能被它的对话说服。由此,聊天机器人可能化身一个非常强大的工具,具体取决于控制该机器人的人、公司甚至政府。这将是一种非常便捷地操纵人们的方式,还可以将其与对话的跟踪以及可以收集到的有关一个人的不同信息联系起来。由于这种操纵是由用户的个人信息提供养料的,所以它会更加隐蔽,也更加有效。一个系统的真正风险不仅在于它可能给人们错误的信息,还在于它可能以有害的方式在情感上操纵他们。
防止以上的负面后果可能并不容易,尤其是随着人工智能系统变得更加复杂,其对话能力只会不断提高,这意味着伊莱扎效应不太可能很快就消失。因此,我们所有人都有责任继续与技术一起成长和适应,这需要的是每个人都具有更批判的心态。这里所说的“每个人”既包括部署系统的人,也涵盖使用系统的人。它始于开发者,终于用户。
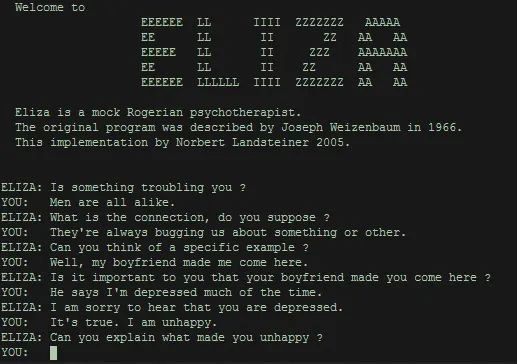
约瑟夫·魏岑鲍姆开发的ELIZA 原始界面截图
2023年4月16日,CBS主持人斯科特·佩利(Scott Pelley)在“60分钟”节目中采访谷歌首席执行官皮查伊,谈及人工智能的未来。皮查伊承认人工智能模型“黑盒子”的存在:“你知道,你并不完全明白。你不能完全说出它为什么这么说,或者为什么它错了。我们有一些想法,随着时间的推移,我们理解这些想法的能力会越来越好。但这就是最先进的地方。”佩利尖锐地质问道:“你不完全了解它是如何运作的,但你却把它释放于社会?”
皮查伊辩解说,这场辩论正在进行当中,他指出:“对此有两种看法。有一组人认为,看,这些只是算法。它们只是在重复在网上看到的东西。然后有一种观点认为,这些算法显示出新兴的特性,有创造力,有推理,有计划,等等,对吗?我个人认为,我们需要以谦逊的态度对待这个问题。”
换句话说,大人工智能公司的路线是功利主义的计算,即使程序可能有危险,发现和改进它们的唯一方法是发布它们,让公众去冒风险。通过邀请用户将聊天机器人想象成像人一样的东西,要求人们忍受它的行为,或者号召人们耐心地训练它变得更好,大人工智能公司巧妙地逃避了责任,要么是将人工智能系统夸大为比实际情况更自主和更有能力。
公众该从这样的幻觉中觉醒了。以谦逊的态度来对待人工智能,意味着不要把范围无尽的、未经测试的系统推出来,简单期望世界能够处理;意味着要考虑到人工智能技术所影响的人的需求和经验;意味着开发人员、监管机构和用户需要共同努力,找到确保以负责任和合乎道德的方式使用 AI 的方法。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}